早几年出现的折叠屏没能拯救颓势的手机市场,直接证据就是去年全球出货量依旧拉胯,同比下滑3.2%至11.7亿部,为近十年来最低。
好在Q4出现了些许回暖,全球和中国市场分别有8.5%和1.2%的同比增幅,尤其是后者,在连续同比下降10个季度后首次转正。
很难说这其中没有AI的功劳。
2023下半年起,以谷歌、三星、OPPO为代表的厂商将大模型内置于智能手机中,完成从云端AI向终端AI的转变,AI手机浪潮正式开启。
IDC更是预测,2024年全球新一代AI手机出货量将达1.7亿部,占智能手机总出货量的近15%。
于是,AI就成了比折叠屏更有效的“救命稻草”,但在产业链眼里,TA更像是一颗“摇钱树”。
端侧AI能省钱
高通曾在去年9月出过一份报告,标题言简意赅——混合AI是AI的未来。
这份报告的核心是高通借大模型云端推理的“宕机”现象,再次向市场强调终端和云端协同工作的混合AI才是真正的首选。
所谓混合AI,是在以云为中心的场景下,终端将根据自身能力,在可能的情况下从云端分担AI工作负载;而在其他场景下,计算将主要以终端为中心,必要时向云端分流任务。
高通的逻辑是,类比传统计算从大型主机和瘦客户端演变为当前云端和PC、智能手机等边缘终端相结合的模式,生成式AI也将形成云端和终端结合的形式。
但这份报告的真正意图,是高通提出的两个趋势:
AI算力将由现在的云端集中部署逐渐转变为云端与终端灵活分配;大模型将逐渐向终端渗透。
事实上,在高通拿出这份报告前,它的那些合作伙伴早就这么干了,而之所以跑的快,不仅是对未来趋势的准确预判,更重要的是省钱。
算法交易公司Deep Trading的创始人Yam Peleg曾算过一笔账,8K版本的ChatGPT云端推理成本为0.0049美分/千token(128个A100 GPU)。以全球1.8亿日活跃用户、每人每天100千token推理需求测算,ChatGPT4在云端进行推理的成本约为88.2万美元/天。
如果换到用户量更大的智能手机上呢?
按照vivo副总裁周围公布的数据,vivo大模型单次对话成本约为0.012-0.015元/次,当前vivo全国用户数约为3亿。以2.5亿日活用户(假设的未来渗透率天花板)、每人每天10次对话需求测算,vivo大模型每天云端推理的成本就要3000万-3750万人民币。
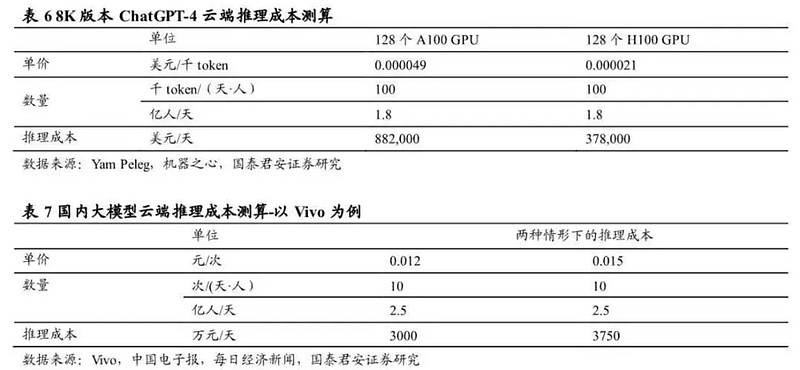
假设以50%分流率计算,将一半的推理分流至端侧进行,那么vivo每年将节约55-68亿人民币的云端运算成本。
看在钱的份上,不搞端侧AI都不行。只是,手机厂商虽然目标高度一致,但在解决大模型手机内存瓶颈的问题上,却出现了分歧。
三条路线
众所周知,大型语言模型的泛化能力及通用性取决于其参数量,如GPT-4拥有16个专家模型,共包含1.8万亿个参数。大多数大模型都在具有强大服务器硬件支持的云端运营,若直接部署于终端设备,则需要设备拥有足够大的内存。
哪怕参数量较小的主流AI大模型也有70亿或130亿参数,分别需要约14GB和20GB的内存。例如有70亿参数的小型LLaMA,其FP16版本大小为14GB,远超当前手机的内存承载能力。
为了解决这个难题,当前主要有三种技术路线:一是直接拔高终端内存,二是压缩大模型体积,三是优化内存调用逻辑。
三条路线分别对应着三个阵营,以微软、联想、OPPO为代表的势力致力于大模型压缩路线,苹果拟通过优化闪存交互和内存管理逻辑来解决内存壁垒,希望通过直接拔高终端内存以突破瓶颈的3DDram技术,代表则是内存厂商。
首先来看规模化最多的大模型压缩,主要包括量化、剪枝及蒸馏等几种方案。
大模型压缩翻译过来其实就是在不影响性能的前提下缩减模型的资源占用。比如通过INT4量化技术支持,AquilaChat2-34B仅需接近7B级别模型的GPU资源消耗,即可提供超过Llama2-70B模型的性能,同时内存占用大幅降低70%,而综合性能指标仅降低了0.7%。
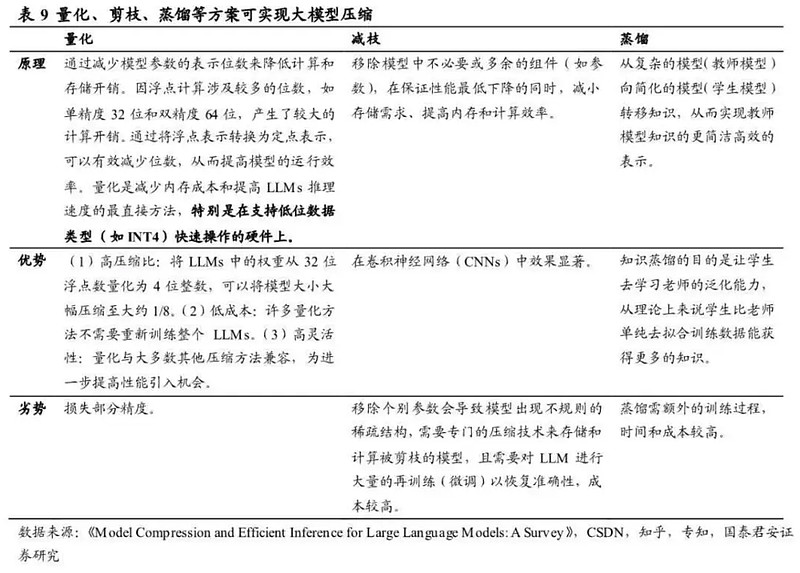
再比如属于剪枝方案的微软SliceGPT技术,实验数据显示,该技术可以为LLAMA-2 70B、OPT 66B和Phi-2模型去除多达25%的模型参数(包括嵌入),同时分别保持密集模型99%、99%和90%的零样本任务性能。
其次是优化内存管理。如前文所分析,70亿参数的模型仅加载参数就需要超过14GB的内存,这超出了大多数智能手机的能力。
苹果提出将模型参数存储在至少比DRAM大一个数量级的闪存上,然后在推理过程中直接且巧妙地从闪存中加载所需的参数。
具体而言,苹果构建了一个以闪存为基础的推理成本模型,并使用窗口化(Windowing)以及行列捆绑(Row-Column Bundling)两项关键技术,来最小化数据传输并最大化闪存吞吐量。
更具体的技术实现步骤这里就不做赘述,总之苹果的闪存方法实现了可以运行比设备DRAM容量大两倍的模型,并在CPU和GPU上分别比传统方法提速4-5倍和20-25倍。
美光CEO此前的说法是,AI手机的内存容量预计将比当今非AI旗舰手机高出50%到100%。除了压缩和优化,还有一个看似是笨办法的办法就是直接拔高终端内存,也就是3D Dram(垂直存储器)技术。
3D Dram是一种利用垂直堆叠方式,将存储单元置于一个二维阵列中,通过垂直叠加显著提高容量的技术。相当于盖起了复式,降低平面面积占用的同时,增加单位面积内的存储容量,从而实现容量的最大化。
根据Neo Semiconductor的估计,3D X-DRAM技术可以跨230层实现 128Gb的密度,是当前DRAM密度的八倍。NEO提出每十年容量增加8倍的目标,目标是在2030年至2035年间实现1Tb容量,比目前DRAM核心容量增加64倍。
谁能受益?
虽然路线不同,但在可行性的前提,各个阵营都能达到一定程度上的预期效果。
比如芯片厂,无论是高通还是联发科,都在推行端侧AI下的大模型压缩,目的自然是为了让下一代芯片能够支撑起手机厂商嵌入大模型的需求。只要完成了这个需求,它们就能是率先吃到红利的一方。
复盘4G到5G的迭代过程,高通就是靠着特殊供需关系,直接将手机厂商的芯片采购成本翻了一倍。
以三星为例,GalaxyS20 Ultra(12G+256G)物料成本中,骁龙865 SoC的整体成本超过150美元,比2019年上半年不包含X50基带的骁龙855 4G移动平台贵1倍左右。
芯片厂对手机厂商又有绝对的议价权,供需失衡下价格掌控能力更强的一方,是很乐意把支持端侧AI的SoC价格打上去的。
在SoC之外,还有一个零部件能在这波AI升级中受益,但可能很多人想不到。
在三星S24系列的拆机结果中,人们发现不仅石墨散热片有额外增加,连平均散热板面积也被提升了,算下来S24、S24+、S24 Ultra分别大了1.5、1.6、1.9倍。
最后测算下来,S24 Ultra里增加的散热材料,相较上一代5G手机每部多出来11元。若考虑高性能、高价格的石墨烯渗透率提高带来的价值增量,还能再增加3块钱。
还有一个零部件,是类似SoC的内存。
根据前文所述,在大模型体积压缩、优化内存调用逻辑、3DDram技术发展等三路线共同作用下,当前16/24GB内存已具备运行端侧大模型的条件,且未来内存容量仍有跨越式提升的空间,容量已不再是桎梏,提升带宽以适应复杂AI任务是更为迫切的需求。
JEDEC固态技术协会已经正式完成了LPDDR 6内存标准的定稿,预计将会在2024年第三季度正式发布,目前LPDDR5X内存的主流带宽为8533Mbps,而LPDDR6带宽可以达到12.8Gbps,比LPDDR5X高出了54%,LPDDR6X更是拥有17Gbps的带宽。
受益于AI手机对高带宽内存的需求,预计LPDDR5/LPDDR5X/LPDDR6将持续供不应求。三星和海力士申请LPDDR6 RAM认证后,将会率先量产LPDDR6内存,同芯片厂一样,供需关系也决定了LPDDR6的涨价。
尾声
作为下游的手机厂,在这场技术迭代革命里是要争取主动的。
AI催生的换机潮确实会带来一波量价齐升,但参考上一轮迭代,仅靠组装而生的手机厂商无法获得大规模溢利。
也就是说,想要吃到更大的红利,尤其在软硬件成本高企的情况下,就必须具备自研能力,比如最重要的大模型和芯片。
当然在今天的环境下,高企的大模型训练成本和供需错配的高性能AI推理芯片,都对手机厂商提出了严峻挑战。但同时具备这两项自研能力的,就有了成本可控及供应稳定的一体化优势。
而其它不具备或不完全具备的厂商,也不是一定会被淘汰。拿捏不了上游,可以转身去拿捏下游。
智能手机的下游,就是移动互联网了。
高度智能化的AI手机应摆脱臃肿、繁多的APP,垂直整合端侧应用,深层次联通各个独立的孤岛,用户一个指令可以调动多个APP自动解决需求,提供一站式服务。
因此,高度智能化的手机必须由其自身来集成各类数据、权限、应用,而单个应用无法这一点,所以天然占据了各项功能入口的手机厂商,就有了取代部分App开发商的可能,进一步瓜分流量及变现。
以智能修图、录音摘要功能为例,运行端侧大模型的AI手机将部分或全部取代孤立的修图类(如美图秀秀)、录音类App(如讯飞听见),此类功能将集成于手机的操作系统中,完全内置于摄像、通话功能中。
对上述App来说,这一切已经发生了,而未来还会有更多App被集成、替代。