一、NVIDIA CUDA 与 AMD ROCm技术基本情况
(一)CUDA技术基本情况
(1)基本概念
CUDA(Compute Unified Device Architecture),是NVIDIA于2007年推出的运算平台,是一种通用并行计算架构,该架构使GPU能够解决复杂的计算问题。它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。开发人员可以使用C语言来为CUDA™架构编写程序,让GPU来处理计算密集型任务。所编写出的程序可以在支持CUDA™的处理器上以超高性能运行。CUDA3.0已经开始支持C++和FORTRAN等高阶编程语言。从简单的角度,可以理解为这是一套英伟达提供给开发人员的编程工具,运用 CUDA 能省下大量撰写低阶语法的时间,进而直接使用高阶语法诸如C++或 Java 等来编写应用于通用 GPU上的演算法,解决平行运算中复杂的问题。
CUDA平台包含了一系列工具函数,有各种功能。
(2)技术架构
CUDA 编程模型中,主要有 Host(主机)和 Device(设备)两个概念,Host 包含 CPU 和主机内存,Device 包含 GPU 和显存,两者之间通过 PCI Express总线进行数据传输。一个完整的 CUDA程序由一系列的设备端函数并行部分和主机端的串行处理部分共同组成,主机和设备能够通过这种方式高效地协同工作,实现 GPU 的加速计算。
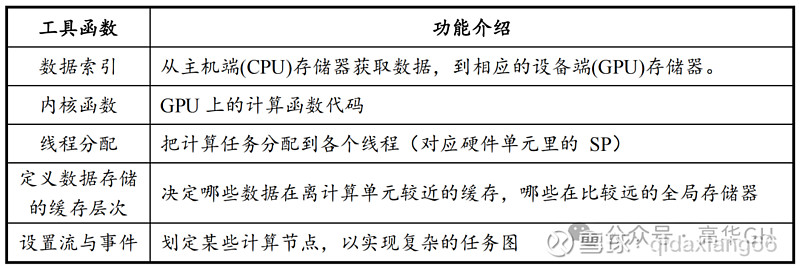
CUDA 在 Host 运行的函数库包括了开发库(Libraries)、运行时(Runtime)和驱动(Driver)三大部分。其中,Libraries 提供了一些常见的数学和科学计算任务运算库,Runtime API 提供了便捷的应用开发接口和运行期组件,开发者可以通过调用 API 自动管理 GPU 资源,而 Driver API 提供了一系列 C 函数库,能更底层、更高效地控制 GPU 资源,但相应的开发者需要手动管理模块编译等复杂任务。
Host中的函数库架构如下图所示:
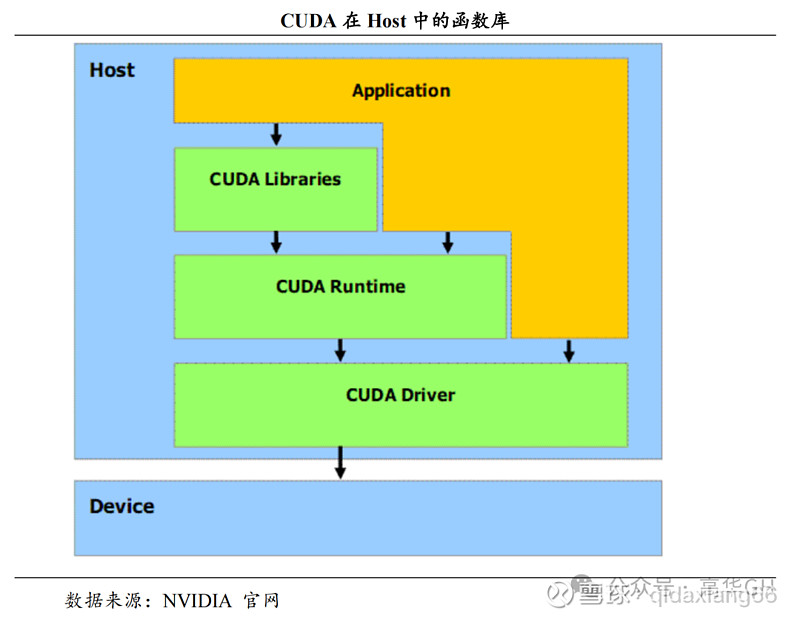
CUDA 在 Device 上执行的函数为内核函数(Kernel)通常用于并行计算和数据处理。在 Kernel 中,并行部分由 K 个不同的 CUDA 线程并行执行 K 次,而有别于普通的 C/C++函数只有 1 次。每一个 CUDA 内核都以一个声明指定器开始,程序员通过使用内置变量__global__为每个线程提供一个唯一的全局 ID。一组线程被称为 CUDA 块(block)。CUDA 块被分组为一个网格(grid),一个内核以线程块的网格形式执行。每个 CUDA 块由一个流式多处理器(SM)执行,不能迁移到 GPU 中的其他 SM,一个 SM 可以运行多个并发的 CUDA 块,取决于CUDA 块所需的资源,每个内核在一个设备上执行,CUDA 支持在一个设备上同时运行多个内核。
Kernel的执行机制如下图所示:
(3)应用场景
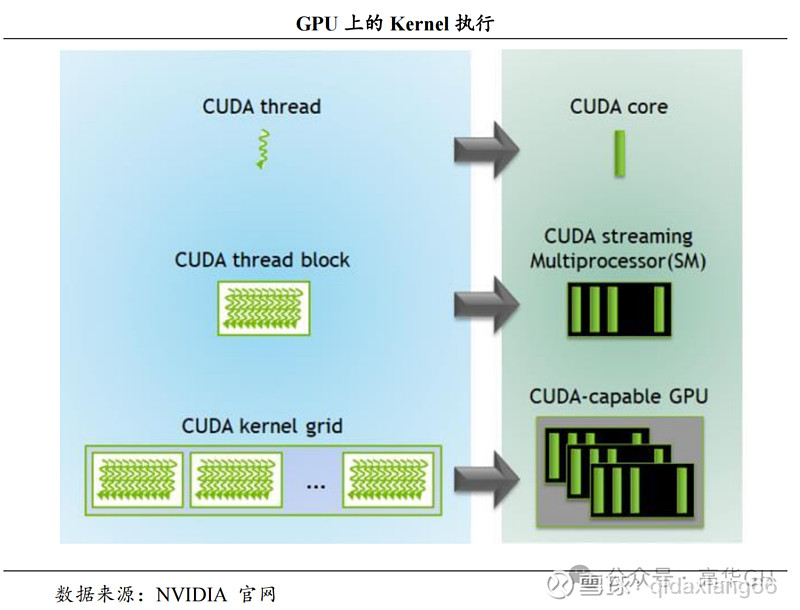
广泛的应用场景与强大生态支持。 CUDA 的应用几乎遍及所有需要大量计算的领域。如:科学研究 (在物理、化学、生物等领域,CUDA 能够加速复杂的模拟和计算过程。比如,模拟宇宙的起源、分析大量的基因序列等。)、深度学习(深度学习需要处理大量的数据和复杂的计算。使用 CUDA,训练神经网络的时间可以从几周缩短到几小时。)、图像处理(从电影的特效制作到医学图像的分析,CUDA 能够加速图像处理的过程,让复杂的图像分析变得更加快速和准确。)、金融分析(在金融领域,CUDA 被用来加速风险分析、市场模拟等计算密集型任务,帮助分析师更快地做出决策。)等。NVIDIA还提供了丰富的文档、教程和工具,让开发者更容易地开发基于 CUDA 的应用。
CUDA应用架构详情如下图所示:
(4)明星产品
Blackwell GPU为NVIDIA最新推出GPU芯片,其包含了2080亿个晶体管,与上一代 Hopper GPU 相比,新型 GPU提供四倍的训练性能和高达 30 倍的推理性能,实现了数据精度进一步降低。Blackwell GPU内置的第二代Transformer引擎,利用先进的动态范围管理算法和细粒度缩放技术(微型tensor缩放)来优化性能和精度,并首度支持FP4新格式,使得FP4 Tensor核性能、HBM模型规模和带宽都实现翻倍。同时Tensor RT-LLM的创新包括量化到4bit精度、具有专家并行映射的定制化内核,能让MoE模型实时推理使用耗费硬件、能量、成本。NeMo框架、Megatron-Core新型专家并行技术等都为模型训练性能的提升提供了支持。
Blackwell GPU的具体性能参数如下图所示:

(二)ROCm技术基本情况
(1)基本概念
ROCm(Radeon Open Computing platforM)是 AMD 于2016年推出的开源软件平台,旨在提供一个可移植、高性能的GPU 计算平台。ROCm 支持多种编程语言、编译器、库和工具,以加速科学计算、人工智能和机器学习等领域的应用。ROCm还支持多种加速器厂商和架构,提供了开放的可移植性和互操作性。
(2)技术架构
ROCm 支持HIP(类 CUDA)和 OpenCL 两种 GPU 编程模型,可实现 CUDA 到 ROCm 的迁移。ROCm支持 AMD Infinity Hub 上的人工智能框架容器,包括TensorFlow、PyTorch、MXNet 等,同时改进了 ROCm 库和工具的性能和稳定性,包括 MIOpen、MIVisionX、rocBLAS、rocFFT、rocRAND 等。
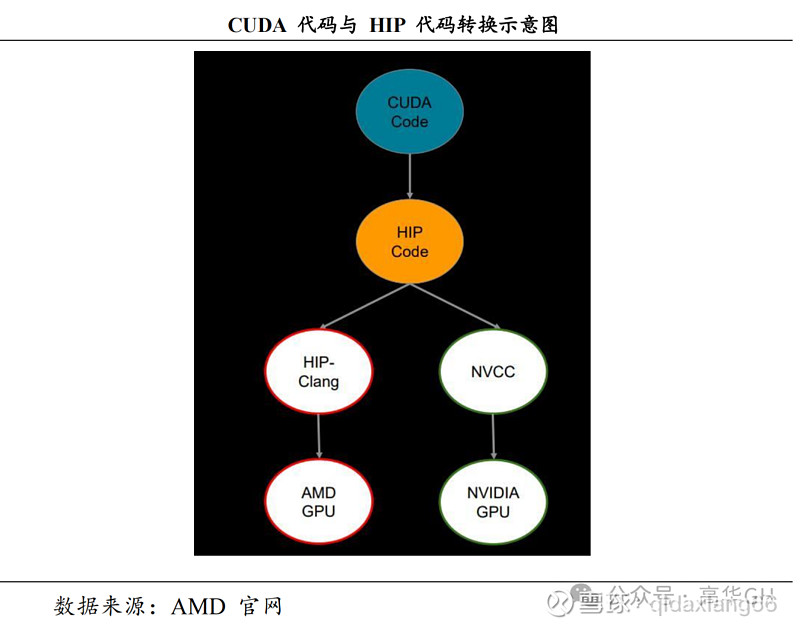
ROCm 的核心是可移植性的异构计算接口 HIP (Heterogeneous Compute Interface for portability), 它可以使得开发者所编写的代码在英伟达CUDA系统下使用。简单地说,从 CUDA 源码可以使用 HIPify 工具转换到 HIP源码上,HIP 源码能够通过不同的编译工具实现在 AMD 或 NVIDIA GPU 这两种 GPU 上运行。ROCm 的最新版本为 ROCm 6,在 MI300 系列上运行ROCm 6 的效能是目前使用 ROCm 5 的 MI250 的 8 倍。
HIP代码转换运行机制如下图所示:
OpenCL(Open Compute Language),是面向异构系统通用并行编程、可以在多个平台和设备上运行的开放标准。OpenCL 支持多种编程语言和环境,并提供丰富的工具来帮助开发和调试,可以同时利用 CPU、GPU、DSP 等不同类型的加速器来执行任务,并支持数据传输和同步。
(3)应用场景
ROCm 目前主要面向超级计算,为高性能计算和机器学习系统提供平台工具,覆盖场景虽落后于CUDA,但已取得重大进展。ROCm曾只包括Radeon Pro 和 Radeon Instinct 等较高端的系列,现已逐步向游戏显卡拓展;支持系统由 Linux 系统拓展至 Windows 系统;已经开始支持主流机器学习框架包括 TensorFlow、Caffe 和PyTorch 等,进一步完善了其 GPU 在机器学习方面的应用。
(4)明星产品
AMD Instinct™ MI300X 独立 GPU,采用最新一代的 AMD CDNA™ 3 架构,为复杂的人工智能和高性能计算应用带来了前所未有的效率和强大性能。这款 GPU 内置了 304 个高效率计算单元,以及专为 AI 设计的多项功能,如对新数据类型的支持、图像和视频解码等,还搭载了创纪录的 192 GB HBM3 内存,确保其作为 GPU 加速器的高性能表现。利用尖端的堆叠芯片与芯片组技术以及多芯片封装,MI300X 不仅推动了生成式 AI、机器学习和推理技术的进步,还在高性能计算加速领域巩固了 AMD 的领先地位。性能上,MI300X 相比前代产品有显著提升,已被应用于全球最快的百万亿级超级计算机。在使用 FP8 和稀疏性的情况下,其在 AI/ML 工作负载上的峰值性能比之前的 AMD MI250X*加速器(使用 FP16MI300-16)提高了 13.7 倍,而在使用 FP32 计算的 HPC工作负载上则有 3.4 倍的性能优势。
MI300X具体芯片构造如下图所示:

CUDA 平台是目前最适合深度学习、AI 训练的GPU 架构。在 2007 年推出后不断改善更新,衍生出各种工具包、软件环境,构筑了完整的生态,并与众多客户合作构建细分领域加速库与 AI 训练模型,已经积累 300 个加速库和 400 个 AI 模型。而竞争对手 AMD 的 ROCm 平台在用户生态和性能优化上还存在差距。
(一) 基础设施差距不大,软件栈ROCm丰富度远低于CUDA
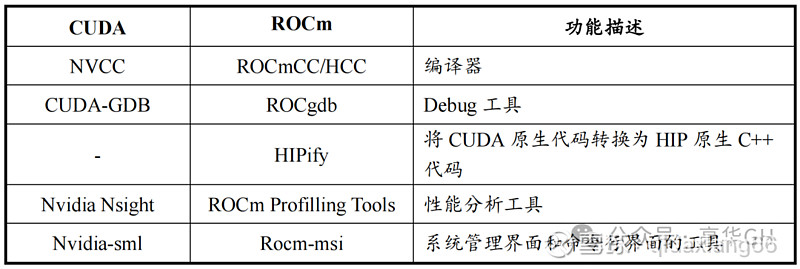
编译器方面,ROCm HCC 通用性更强,NVCC 只针对英伟达硬件去做的,在使用上主要是用户习惯的差异, 其余差异不大。
CUDA与ROCm编译及工具链具体情况如下表列示
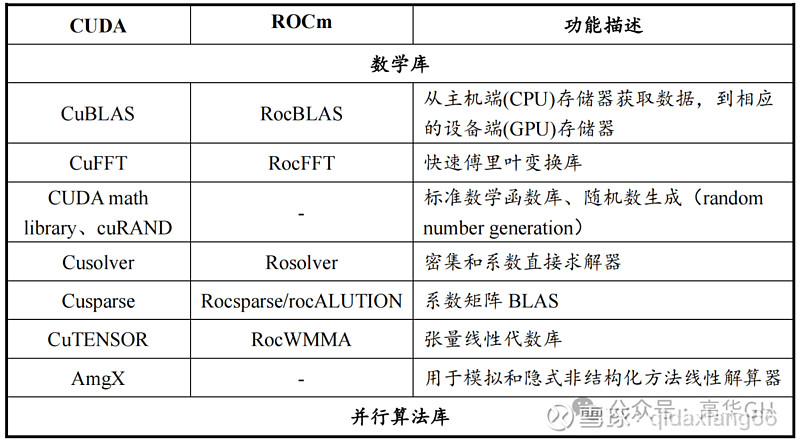
CUDA和ROCm的基础框架提供众多的支持库,包括基础数学库、AI支持库、通信库、并行库等,CUDA的支持库能够为科学计算、医疗服务和LLM等领域提供一条龙解决方案,而ROCm软件库只包括了CUDA中的一些部分功能,如部分数学函数、深度学习库等,主要被研究机构使用,价值量较低,并且在应用场景的拓展上存在较大困难。
CUDA与ROCm软件栈具体情况如下表列示
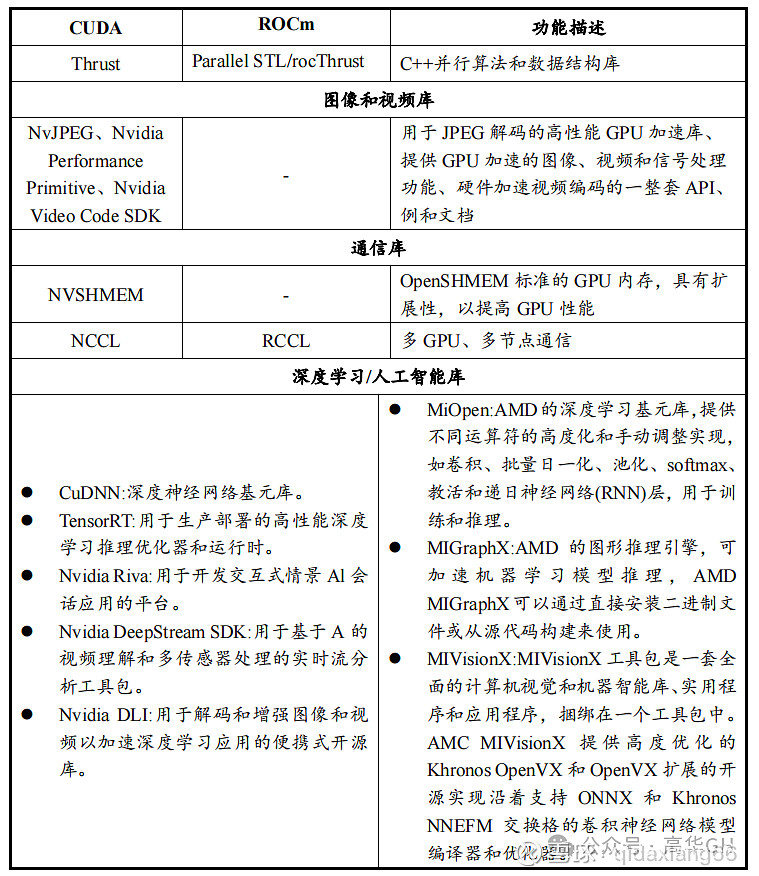
CUDA 能够在科学计算、医疗服务、大模型计算等领域实现完整生态链的解决方案,而AMD一定程度上停留在基础系统部分,竞争力略显不足。
CUDA与ROCm的独家功能对比如下表列示
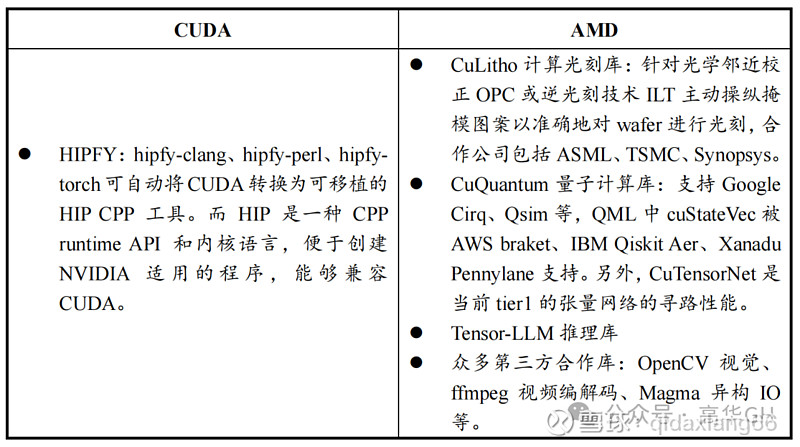
(二)AMD框架迁移能力略显不足,生态圈层与
CUDA存在较大差距
深度学习框架方面,CUDA 在训练推理过程中对开发者需要做框架迁移的支持显著优于 ROCm。深度学习主要包括训练、推理两个部分,训练主要包含前向计算与反向计算,需要反复验证修改参数,对精度要求较高;而推理相对简单,只需一次前向计算得出结果即可。在生产环节中,可以用训练好的AI模型进行特定领域的计算,通过推理得到想要的结果。而ROCm 和CUDA 在训练、推理两方面在使用层面还存在不小差距。CUDA有很多丰富的工具和组件,即之前提到的 AI 软件栈组件,可以帮助开发者在N 卡上或国内其他专门做推理的芯片厂商的卡上运行模型推理,且训练精度高。而ROCm 与目前主流的深度学习框架确实存在一定差距和代沟,例如在 PyTorch、TensorFlow 有适配 ROCm 的工具,但在一些小众的深度学习框架,像 MSI 以及百度、飞桨PaddlePaddle 等都没有,无形中增加了很多门槛,甚至完全不可用。
但相对于已经成熟的 CUDA 系统,其生态系统和工具链的成熟度还有一定差距。它仅支持 Instinct、Radeon 系列产品,而 CUDA 则涵盖了英伟达大部分产品线。且ROCm 的生态系统相对较小,这可能导致较少的第三方库、工具和文档资源可用。CUDA于2007年推出,在技术积累、软硬件协同建设等方面具有巨大的领先优势,而ROCm于2016年推出,AMD作为后发者起步较晚,且研发实力较NVIDIA有所差距,要实现全方位追赶还有很长一段路要走。
综上,从生态圈的角度来讲,CUDA对比ROCm竞争优势明显。
三、市场基本情况及竞争格局
(一)NVIDIA在GPU市场占据主导地位,领先优势明显
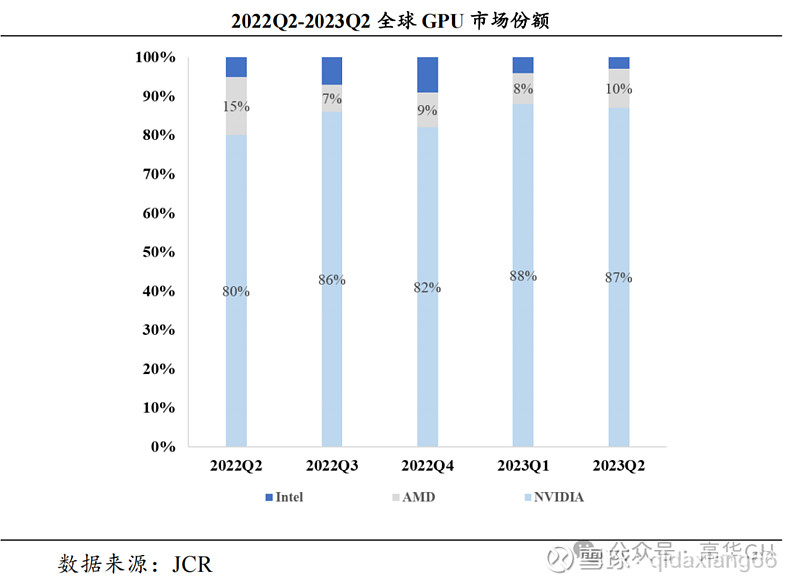
据 JCR,2022Q2 开始,NVIDIA 约占全球 GPU 市场份额 80%以上。2023Q2,NVIDIA约占全球 GPU市场份额高达 87%,AMD 约占 10%,Intel 约占 3%。英伟达正在由GPU显卡供应向软硬件一体AI解决方案供应商的转变后,形成了竞争对手难以企及的平台化优势。
2022Q2-2023Q2全球GPU市场份额占比如下图所示:
(二)CUDA开发用户数量增长迅速,ROCm开源性平台或将加速用户增长
凭借先发优势和长期技术积累,CUDA 生态圈已经具有更高的成熟度和稳定性。这使得开发者能够借助已有的资源和文档进行开发和部署,减少学习曲线和风险,并为英伟达 GPU 的开发、优化和部署多种行业应用提供了独特的先发竞争优势。全球范围内,截至 2020 年,CUDA 开发者数量达到了 200 万,2023年CUDA开发者数量增长至400万,其中包括Adobe等大型企业客户,较高的需求粘性也使得 CUDA的使用者更倾向于使用熟悉的、更兼容的软件,因此更多开发者选择或持续使用CUDA。
AMD 采用开放的软件战略,致力于提供开放源代码的解决方案。AMD 的 ROCm 平台是一个开源项目,允许开发者自由地使用、修改和贡献代码。这种开放性促进了社区的合作和创新,并且使得用户能够更加灵活地定制和优化软件,与此同时,AMD作为后发者起步晚,适用开源生态能够快速增加市场用户,提高市场份额。此外,与软件开发公司和领先的科技企业建立合作伙伴关系是AMD 软件生态系统的重要组成部分。通过与合作伙伴共同开发和优化软件,AMD能够提供更好的兼容性和优化性能,同时能够带来一部分粘性用户。
四、未来发展趋势
成熟且完善的平台生态是 GPU 厂商的护城河。相较于持续迭代的微架构带来的技术壁垒硬实力,成熟的软件生态形成的强大用户粘性将在长时间内塑造 GPU厂商的软实力。
目前NVIDIA在GPU领域的市场壁垒短时间内仍无法被撼动。首先,硬件端来看,英伟达具备超强的研发能力和芯片设计能力,能够不断推出性能更强、功耗更低的产品。而相较于不断迭代的微架构技术,生态所带来的用户粘性在长期竞争中显得更为关键。CUDA 做并行计算的研发时间要早很多,就带来了这种无与伦比的优势。再者,多年来英伟达在这个方向上持续进行研发投入、高校和企业持续应用 CUDA,对其生态的发展都做出巨大贡献,导致当前无论是做训练还是做推理,CUDA 都是最优选择。
相较于竞争对手,AMD 的软件生态系统在一些方面具有不同的特点和优势:ROCm 作为一个开源平台,开发人员可以根据自己的特定需求定制 ROCm;AMD 的软件生态系统广泛支持多个操作系统,包括Windows、Linux 和 macOS。这使得用户能够在各种环境下进行开发和部署,以满足不同的需求。但与 CUDA 相比,ROCm 也存在一些劣势,相对于已经成熟的 CUDA 系统,其生态系统和工具链的成熟度还有一定差距。
综合来看,英伟达凭借其较早布局的先发优势,通过产品性能迭代、软件库、深度学习框架等方面,打造完整生态链,占据市场领先地位。即便AMD 的软件生态系统在开放性、多供应商支持和合作伙伴关系等方面具有优势,短期内,NVIDIA GPU市场主导地位不会改变。NVIDIA较AMD早推出近十年,在这十年中积累了深厚的技术与生态壁垒,能够实现算力驱动下多场景的应用。相比之下,AMD即使打造“类CUDA”生态系统,但要想与NVIDIA相抗衡,仍需要持续不断的技术创新和生态建设。未来双方将展开更激烈的竞争,促使双方不断推出更具创新性和竞争力的产品,促进技术创新发展。